data-ingestion
Data ingestion is an important aspect when users start using the Altergo platform. Data uploaded by the user can be used to visualize trends, create histograms, distrbutions, etc. These visuals provide a method to observe insights into the data without having to sift, clean and visualize the data directly. With the Ion SDK, uploading data is simplified to two methods: updateSensorDataByFile, and updateSensorDataByDirectInsert.
Ingesting data can seem daunting at first (especially for someone without some background in handling DataFrame). To make the process streamlined and easy to understand, we start with understanding the df attribute of the Asset. Next, we shall explore various data sequences that users may face when ingesting data. While these data sequences are not exhaustive, they form the fundamental base for more complex data sequences.
The Ion SDK comes with two methods included within the Client: updateSensorDataByFile, and updateSensorDataByDirectInsert.
What is the df attribute of an asset?
Each asset on Altergo is created to ensure that it has the ability to hold a dataframe which contains data that has been previously ingested, or data that needs to be ingested. The attribute within the asset class that allows us to store dataframes is the df attribute.
The df attribute expects a Pandas DataFrame. Methods defined within the Client use the df attribute to either ingest data into Edison, or to get data from Altergo into an asset.
When to use the updateSensorDataByFile method?
The updateSensorDataByFile method is used to upload large chunks of data to Edison without performing any further analysis on it. The method expects the user to provide a component (comp), and a list of sensors to update (sensorList). The component's df attribute must contain a DataFrame whose column names are the in the list of sensors to update (sensorList). The DataFrame should also be datetime indexed.
By default, the updateSensorDataByFile method will use the first and last datetime from the df to determine the startDate and endDate.
If desired, you can provide the startDate and endDate in datetime format. This is not recommended.
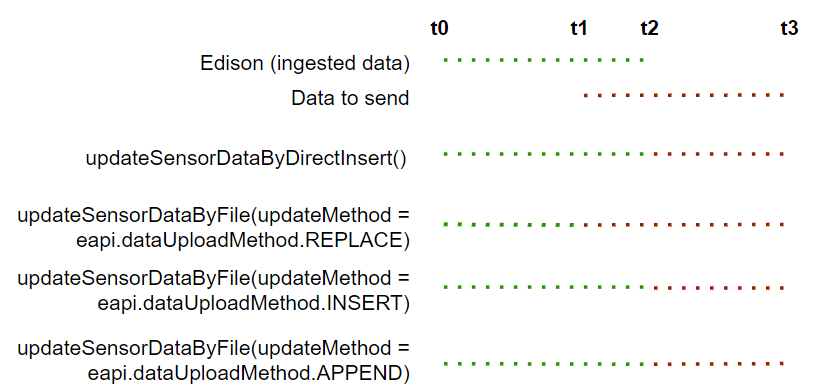
The updateMethod requires an Enum type which can be passed by using the dataUploadMethod. It contains three types: REPLACE, INSERT and APPEND. When set to REPLACE, it allows you to delete and update data prior to the last updated timestamp for the sensor. If updateMethod is set to INSERT, it allows you to insert data where there is a gap. If there is conflict, ingested data has priority. If updateMethod is set to APPEND, all data priotr to last update timestamp are ignored. Only data after the last update timestamp is added.
>>> updateSensorDataByFile(asset, sensorList, updateMethod = dataUploadMethod.REPLACE)
>>> updateSensorDataByFile(asset, sensorList, updateMethod = dataUploadMethod.INSERT)
>>> updateSensorDataByFile(asset, sensorList, updateMethod = dataUploadMethod.APPEND)
Data once erased cannot be restored.
When ingesting data using the updateSensorDataByFile method, the data does not go through any checking for alerts or warranty violations. Thus, this method is best suited for uploading large amount of data
When to use the updateSensorDataByDirectInsert method?
The updateSensorDataByDirectInsert is useful when there is live (or almost live) data that is to be ingested while also performing checks for alerts and warranty violations. This method has similar parameters as the updateSensorDataByFile method. However, there are key difference between the two method. First, in contrast to the updateSensorDataByFile method, the sensorList parameter expects a list of sensor codes instead of sensor names. Further, the columns of the DataFrame must also have the sensor codes instead of sensor names. Second, in contrast to the updateSensorDataByFile method, the updateSensorDataByDirectInsert does not have an updateMethod parameter. Through the updateSensorDataByDirectInsert method, data is always inserted in the timestamp, if possible- in case of conflicting data, ingested data is given priority (incoming data is rejected).
Example Cases of Data Ingestion
Case 1
Case 2

Case 3
